
Ajay Narayanan
Member
Greetings!
I posted this on cloudynights, but I think there are more linux users here and this may be of interest.
I was able to successfully install cuda, and gpu enabled tensorflow libraries, and run starnet++ using these under linux. I found a similar set of steps for Windows from Darkarchon here: https://www.darkskie...t-starnet-cuda/ . I followed those general ideas and adapted them to linux.
This is more in the form of a report. I cannot help with installation or troubleshooting questions. I am also not a software engineer but a long time linux user and occasional script level programmer for my personal installations only.
My system
AMD 3900X, 32 GB
Nvidia GeForce GTX 1660 Super, Driver Version: 510.47.03, Compute (cuda) Version: 7.5
Linuxmint 20.3 with the xfce4 desktop. This distribution is based on Ubuntu 20.04.
Nvidia's list of cuda enabled GPUs are listed here: https://developer.nvidia.com/cuda-gpus but this list is incomplete. For example, It does not list the GeForce GTX 1660 Super. The 1660 Super supports CUDA 7.5. According to Darkarchon, starnet needs CUDA 3.5 or higher.
https://en.wikipedia...rocessing_units [cuda version is listed under supported API's]
https://www.techpowerup.com/gpu-specs/ [cuda version is listed under Graphics Features]
Installed cuda
The cuda toolkit is here: https://developer.nv...toolkit-archive . The documentation is a very long read. Here are the steps that I took.
Cuda install requires the build-essential package as a dependency. However build-essential would not install with libc6 version 2.31-0ubuntu9.3 that I initially had on my system. On March 3, 2022, after libc6 updated to 2.31-0ubuntu9.7 build-essential and everything else installed smoothly.
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install build-essential
I then went to https://developer.nv...toolkit-archive and clicked the following links in turn to get the quick install instructions.
CUDA Toolkit 11.6.1 -> Linux -> x86_64 -> Ubuntu -> 20.04 -> deb (local).
Installation Instructions for my distribution:
$ wget https://developer.do...-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ wget https://developer.do....03-1_amd64.deb
$ sudo dpkg -i cuda-repo-ubuntu2004-11-6-local_11.6.1-510.47.03-1_amd64.deb
$ sudo apt-key add /var/cuda-repo-ubuntu2004-11-6-local/7fa2af80.pub
$ sudo apt-get update
$ sudo apt-get -y install cuda
$ apt install libcudnn8 should be $ sudo apt-get install -y libcudnn8
After these steps, the required cuda components are installed in /usr/local/
Some development tools and ide are also included. I ignore these.
Installed libtensorflow-gpu
Found it here: https://www.tensorfl.../install/lang_c and followed install instructions.
$ sudo tar -C /usr/local -xzf libtensorflow-gpu-linux-x86_64-2.7.0.tar.gz
$ sudo ldconfig /usr/local/lib
Doing ldconfig ensures that programs will find the tensorflow libraries from the /usr/local install.
Then I moved the included libtensorflow libraries to a temporary location so that the gpu enabled libraries in /usr/local were picked up. Otherwise the cpu versions are used.
For the commandline version of starnet++ V2:
In the directory that contains the starnet++ command line files [such as StarNetv2CLI_linux/] I did the following.
$ mkdir temp
$ mv libtensorflow* ./temp/
For Pixinsight: The tensorflow libraries are in /opt/PixInsight/bin/lib
$ mkdir /opt/temp
$ mv libtensorflow* /opt/temp
Be warned here! You will need to use super user privileges to do this. You could damage your Pixinsight installation if you are not careful.
Set environment variables
$ export TF_FORCE_GPU_ALLOW_GROWTH="true" [I put this in my bashrc so that it is set every session.}
Why is this needed? See https://www.tensorflow.org/guide/gpu
Quote: "In some cases it is desirable for the process to only allocate a subset of the available memory, or to only grow the memory usage as is needed by the process. TensorFlow provides two methods to control this.
The first option is to turn on memory growth by calling tf.config.experimental.set_memory_growth, which attempts to allocate only as much GPU memory as needed for the runtime allocations: it starts out allocating very little memory, and as the program gets run and more GPU memory is needed, the GPU memory region is extended for the TensorFlow process.
Another way to enable this option is to set the environmental variable TF_FORCE_GPU_ALLOW_GROWTH to true. This configuration is platform specific."
Using Multiple GPUs
I only have a single GPU. However, controlling how many cards or which cuda capable card is enabled is achieved via the environment variable CUDA_VISIBLE_DEVICES as documented here: https://docs.nvidia....x.html#env-vars
"Only the devices whose index is present in the sequence are visible to CUDA applications and they are enumerated in the order of the sequence. If one of the indices is invalid, only the devices whose index precedes the invalid index are visible to CUDA applications. For example, setting CUDA_VISIBLE_DEVICES to 2,1 causes device 0 to be invisible and device 2 to be enumerated before device 1. Setting CUDA_VISIBLE_DEVICES to 0,2,-1,1 causes devices 0 and 2 to be visible and device 1 to be invisible."
GPU indices are enumerated starting from 0. If you have two GPUs that you wish to use, set the environment variable as follows for Linux:
export CUDA_VISIBLE_DEVICES="0" [0nly the first card is visible to cuda applications]
export CUDA_VISIBLE_DEVICES="0,1" [Use first card before the second]
export CUDA_VISIBLE_DEVICES="1,0" [Use second card before the first]
export CUDA_VISIBLE_DEVICES="2,1" [Causes device 0 to be invisible and device 2 to be enumerated before device 1]
export CUDA_VISIBLE_DEVICES="0,2,-1,1" [Make devices 0 and 2 to be visible and device 1 to be invisible because -1 is an invalid index]
Again one would set this variable as needed in one's bashrc. See the link at the top for Darkarchon's instructions on how to set environment variables in Windows.
Error/Warning message on console
There was an error message in the terminal running starnet++ from the command line:
"I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero."
This does not seem to matter. It can be dealt with by running the following command (once per session) in the terminal as described here: https://github.com/t...ow/issues/42738
$ for a in /sys/bus/pci/devices/*; do echo 0 | sudo tee -a $a/numa_node; done
If you use starnetGUI. [https://www.cloudyni...6#entry11695043], or the PI module, you will not see this warning message.
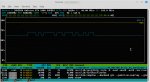
Installed nvtop to monitor gpu usage
$ sudo apt install nvtop
nvtop is run from the command line in a terminal. When starnet++ is running an entry is shown under Type as "Compute" whereas normal display tasks are listed as "Graphic." The line graph shows memory and gpu usage. This should go up when starnet++ is running.
Results
1) From the command line I ran starnet++ as an argument to the time command to get a time estimate:
$ time ./starnet++ ~/PI/NGC700_Drzl2_Ha_nonlinear.tif fileout.tif 64
[Yes, there's a typo in the input filename, should have been NGC7000. Also a stride of 64 is overkill with this new version, but this was for benchmarking and figuring out the wonders of gpu acceleration for the first time!]
Reading input image... Done! Bits per sample: 16, Samples per pixel: 1
Height: 5074 Width: 6724...Done!
Output of the time command:
real 5m35.637s <----- This is good!
user 5m39.473s
sys 0m1.908s
2) Tried the new Starnet2 PI module for Linux with PI version 1.8.9-20220313.
Works fine with nonlinear 16 bit Tiff: Image size: 6724x5074, Number of channels: 1, Color space: Grayscale, Bits per sample: 16
Stride: 256
Processing 540 image tiles: done
Done! 25.716 s
Stride: 128
Processing 2120 image tiles: done
Done! 01:03.93
Also works on linear version of this 2xDrizzled file but only if its upsampled.
Resampling to 13448x10148 px, Lanczos-3 interpolation, c=0.30: done, Window size: 512, Stride: 256
Image size: 13448x10148
Processing 2120 image tiles: done
Resampling the image to original size...
Done! 01:28.12
Many thanks to Nikita Misiura (Starnet++), JJ Teoh (starnet GUI) and Darkarchon (instructions for windows) and of course all the PI devs.
Cheers!
Ajay
I posted this on cloudynights, but I think there are more linux users here and this may be of interest.
I was able to successfully install cuda, and gpu enabled tensorflow libraries, and run starnet++ using these under linux. I found a similar set of steps for Windows from Darkarchon here: https://www.darkskie...t-starnet-cuda/ . I followed those general ideas and adapted them to linux.
This is more in the form of a report. I cannot help with installation or troubleshooting questions. I am also not a software engineer but a long time linux user and occasional script level programmer for my personal installations only.
My system
AMD 3900X, 32 GB
Nvidia GeForce GTX 1660 Super, Driver Version: 510.47.03, Compute (cuda) Version: 7.5
Linuxmint 20.3 with the xfce4 desktop. This distribution is based on Ubuntu 20.04.
Nvidia's list of cuda enabled GPUs are listed here: https://developer.nvidia.com/cuda-gpus but this list is incomplete. For example, It does not list the GeForce GTX 1660 Super. The 1660 Super supports CUDA 7.5. According to Darkarchon, starnet needs CUDA 3.5 or higher.
https://en.wikipedia...rocessing_units [cuda version is listed under supported API's]
https://www.techpowerup.com/gpu-specs/ [cuda version is listed under Graphics Features]
Installed cuda
The cuda toolkit is here: https://developer.nv...toolkit-archive . The documentation is a very long read. Here are the steps that I took.
Cuda install requires the build-essential package as a dependency. However build-essential would not install with libc6 version 2.31-0ubuntu9.3 that I initially had on my system. On March 3, 2022, after libc6 updated to 2.31-0ubuntu9.7 build-essential and everything else installed smoothly.
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install build-essential
I then went to https://developer.nv...toolkit-archive and clicked the following links in turn to get the quick install instructions.
CUDA Toolkit 11.6.1 -> Linux -> x86_64 -> Ubuntu -> 20.04 -> deb (local).
Installation Instructions for my distribution:
$ wget https://developer.do...-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ wget https://developer.do....03-1_amd64.deb
$ sudo dpkg -i cuda-repo-ubuntu2004-11-6-local_11.6.1-510.47.03-1_amd64.deb
$ sudo apt-key add /var/cuda-repo-ubuntu2004-11-6-local/7fa2af80.pub
$ sudo apt-get update
$ sudo apt-get -y install cuda
After these steps, the required cuda components are installed in /usr/local/
Some development tools and ide are also included. I ignore these.
Installed libtensorflow-gpu
Found it here: https://www.tensorfl.../install/lang_c and followed install instructions.
$ sudo tar -C /usr/local -xzf libtensorflow-gpu-linux-x86_64-2.7.0.tar.gz
$ sudo ldconfig /usr/local/lib
Doing ldconfig ensures that programs will find the tensorflow libraries from the /usr/local install.
Then I moved the included libtensorflow libraries to a temporary location so that the gpu enabled libraries in /usr/local were picked up. Otherwise the cpu versions are used.
For the commandline version of starnet++ V2:
In the directory that contains the starnet++ command line files [such as StarNetv2CLI_linux/] I did the following.
$ mkdir temp
$ mv libtensorflow* ./temp/
For Pixinsight: The tensorflow libraries are in /opt/PixInsight/bin/lib
$ mkdir /opt/temp
$ mv libtensorflow* /opt/temp
Be warned here! You will need to use super user privileges to do this. You could damage your Pixinsight installation if you are not careful.
Set environment variables
$ export TF_FORCE_GPU_ALLOW_GROWTH="true" [I put this in my bashrc so that it is set every session.}
Why is this needed? See https://www.tensorflow.org/guide/gpu
Quote: "In some cases it is desirable for the process to only allocate a subset of the available memory, or to only grow the memory usage as is needed by the process. TensorFlow provides two methods to control this.
The first option is to turn on memory growth by calling tf.config.experimental.set_memory_growth, which attempts to allocate only as much GPU memory as needed for the runtime allocations: it starts out allocating very little memory, and as the program gets run and more GPU memory is needed, the GPU memory region is extended for the TensorFlow process.
Another way to enable this option is to set the environmental variable TF_FORCE_GPU_ALLOW_GROWTH to true. This configuration is platform specific."
Using Multiple GPUs
I only have a single GPU. However, controlling how many cards or which cuda capable card is enabled is achieved via the environment variable CUDA_VISIBLE_DEVICES as documented here: https://docs.nvidia....x.html#env-vars
"Only the devices whose index is present in the sequence are visible to CUDA applications and they are enumerated in the order of the sequence. If one of the indices is invalid, only the devices whose index precedes the invalid index are visible to CUDA applications. For example, setting CUDA_VISIBLE_DEVICES to 2,1 causes device 0 to be invisible and device 2 to be enumerated before device 1. Setting CUDA_VISIBLE_DEVICES to 0,2,-1,1 causes devices 0 and 2 to be visible and device 1 to be invisible."
GPU indices are enumerated starting from 0. If you have two GPUs that you wish to use, set the environment variable as follows for Linux:
export CUDA_VISIBLE_DEVICES="0" [0nly the first card is visible to cuda applications]
export CUDA_VISIBLE_DEVICES="0,1" [Use first card before the second]
export CUDA_VISIBLE_DEVICES="1,0" [Use second card before the first]
export CUDA_VISIBLE_DEVICES="2,1" [Causes device 0 to be invisible and device 2 to be enumerated before device 1]
export CUDA_VISIBLE_DEVICES="0,2,-1,1" [Make devices 0 and 2 to be visible and device 1 to be invisible because -1 is an invalid index]
Again one would set this variable as needed in one's bashrc. See the link at the top for Darkarchon's instructions on how to set environment variables in Windows.
Error/Warning message on console
There was an error message in the terminal running starnet++ from the command line:
"I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero."
This does not seem to matter. It can be dealt with by running the following command (once per session) in the terminal as described here: https://github.com/t...ow/issues/42738
$ for a in /sys/bus/pci/devices/*; do echo 0 | sudo tee -a $a/numa_node; done
If you use starnetGUI. [https://www.cloudyni...6#entry11695043], or the PI module, you will not see this warning message.
Installed nvtop to monitor gpu usage
$ sudo apt install nvtop
nvtop is run from the command line in a terminal. When starnet++ is running an entry is shown under Type as "Compute" whereas normal display tasks are listed as "Graphic." The line graph shows memory and gpu usage. This should go up when starnet++ is running.
Results
1) From the command line I ran starnet++ as an argument to the time command to get a time estimate:
$ time ./starnet++ ~/PI/NGC700_Drzl2_Ha_nonlinear.tif fileout.tif 64
[Yes, there's a typo in the input filename, should have been NGC7000. Also a stride of 64 is overkill with this new version, but this was for benchmarking and figuring out the wonders of gpu acceleration for the first time!]
Reading input image... Done! Bits per sample: 16, Samples per pixel: 1
Height: 5074 Width: 6724...Done!
Output of the time command:
real 5m35.637s <----- This is good!
user 5m39.473s
sys 0m1.908s
2) Tried the new Starnet2 PI module for Linux with PI version 1.8.9-20220313.
Works fine with nonlinear 16 bit Tiff: Image size: 6724x5074, Number of channels: 1, Color space: Grayscale, Bits per sample: 16
Stride: 256
Processing 540 image tiles: done
Done! 25.716 s
Stride: 128
Processing 2120 image tiles: done
Done! 01:03.93
Also works on linear version of this 2xDrizzled file but only if its upsampled.
Resampling to 13448x10148 px, Lanczos-3 interpolation, c=0.30: done, Window size: 512, Stride: 256
Image size: 13448x10148
Processing 2120 image tiles: done
Resampling the image to original size...
Done! 01:28.12
Many thanks to Nikita Misiura (Starnet++), JJ Teoh (starnet GUI) and Darkarchon (instructions for windows) and of course all the PI devs.
Cheers!
Ajay
Attachments

Last edited: