
Newbie question, I am also considering a new desktop computer optimized for working with Pixinsight. What attributes are most important? More memory? More cores? Where is the marginal benefit in processing speed? Does the graphics card matter?
I bought a Dell computer in 2017 which worked great with PI. I just got StarXterminator and it brings my computer to its knees. Many minutes to remove stars from a single frame. Am I being to hard on myself and expecting too much?
I'd welcome any feedback.
Thanks,
Jay Landis
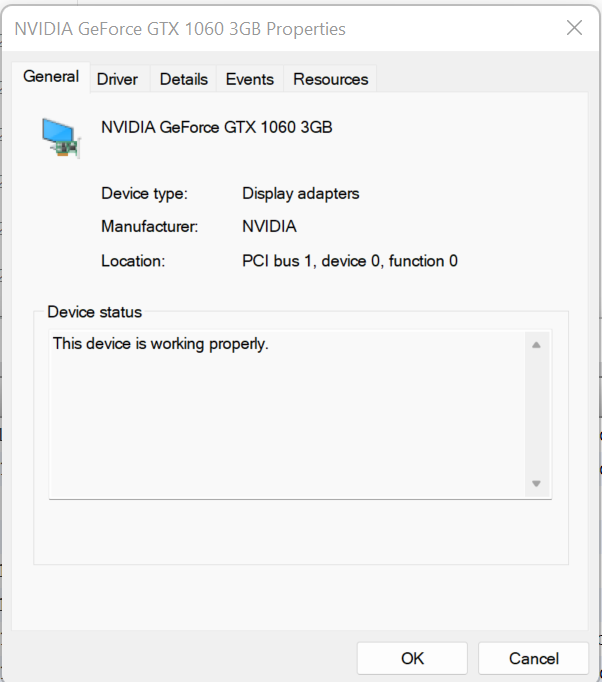
StarNet and the XTerminator tools take minutes to run even on a fast CPU. But with a CUDA capable GPU you can cut it down to half a minute. It doesn't even have to be the latest and greatest; check out the capability link in my tutorial:
https://rikutalvio.blogspot.com/2023/02/pixinsight-cuda.html
You kind of need it all for PixInsight; a fast CPU will help you the most, but for preprocessing you also need lots of RAM and fast storage (nvme) if you have large datasets.
Last edited:
")